The first segmentation phase started with experiments for comparing different approaches to segmentation. Using the pilot test corpus, annotators were instructed to apply existing annotation schemes based on prosodic criteria (GAT), on pragmatic criteria, on syntactic criteria and on the hybrid approach of « macro-syntaxe ». The experiments clearly showed that corpus-wide segmentation is best approached via syntactic criteria for reasons of robustness, inter-rater reliability and efficiency. The experiments also resulted in a first version of an inventory of segmentation problems. Results of the first phase were presented in Biagio et al. (2017).
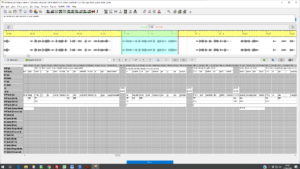
Consequently, the first version of the guidelines (Westpfahl et al. 2018c) was developed as a detailed syntactic annotation scheme based on the theory of topological fields. Categories underlying the segmentation process – fields, clauses and maximal syntactic units — were made explicit in these guidelines in order to make annotators’ decisions maximally transparent and, on that basis, iteratively refine the guidelines by identifying and clarifying difficult cases. The complete pilot corpus was annotated according to these guidelines and evaluated for inter-annotator agreement. Results of this work package were published as Westpfahl/Gorisch (2018b).
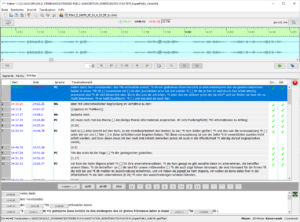
With the first version of the guidelines sufficiently stabilized and validated, and the extended test corpus ready, the final version of the guidelines (Westpfahl et al. 2019b) was developed as a simplified version of Westpfahl et al. (2018c). It concentrates on maximal syntactic units and their classification into classes of sentential vs. non-sentential, simple vs. complex and completed vs. aborted units (with a remainder category « uninterpretable »), formulates concrete practical instructions for use with the FOLKER annotation tool, and thus optimizes the efficiency of the segmentation process. The final version of the guideline was applied to the entire extended test corpus and validated again for inter-annotator agreement. The resulting segmented data was analysed quantitatively with respect to dependencies between segment and interaction types (Westpfahl/Gorisch/Schmidt 2018e), and a study on syntactic disruptions (Strub/Westpfahl 2018) carried out.